Table of Contents
Human Capital
Programming Language
Development Environment
Computing and Storage
Deployment
Human Capital
Subject Matter Expert / User
If you’re using data science to solve a problem, you first need to understand the problem. Talking to an “end user” or subject matter expert is invaluable to gaining understanding of the problem / context. What’s more, even if you build a great machine learning model that makes accurate predictions, it’s useless if the model does not fit cleanly within a user’s existing workflow (who wants another box / computer at their workstation?). If your end user doesn’t intuitively know how to interact with the model or doesn’t understand how the model arrived at the results, your tool will not be used. Building software that integrates within existing workflows and solves user pain points requires working closely with users.
Business Owner
The problem owner may not be the person on the ground that is experiencing problems, but they have responsibility for solving them. For example, you may be building an image detection algorithm to help an intelligence analyst more easily find enemy supply trucks, but it’s the intelligence company commander who is ultimately responsible. This person may have a higher-level view of the workflow beyond just the end user, can challenge/validate your assumptions about the problem, and serve as an advocate for the organization you’re working for.
Data Scientist
The role of ‘data scientist’ can often mean many things, up to and including a data engineer. Oftentimes, there are different types of data scientists that will overlap in their respective roles and functions. So, at the risk of some oversimplification, there are two general, overlapping, types of data scientists (it is also worth mentioning that many statisticians also fit within this framework, although their approach to data will be markedly different).
- Data Intelligence Analysts are your ‘front-facing’ data scientists. Their work is often far more heavily weighted in dealing with stakeholders, relating analysis to business metrics, and data visualization, and less weighted toward model tuning and development and performing rigorous empirical investigations or tests. They are generally good at understanding the business problem, mapping a well-known data science technique to it, to deliver quick insights.
- Machine Learning Engineers are your ‘rear-facing’ data scientists. Their work will be primarily in the range of optimizing models and features to best meet a certain machine learning task. They are generally much more skilled in mathematics and computer programming and are generally good at taking a well-scoped data science problem and delivering an optimal model.
Data Engineer
Builds and maintains the platforms that bring (1) enough, (2) clean, (3) timely data to the data scientists. The Data Engineering Cookbook by Andreas Kretz is an excellent resource to learn more.
UX/UI Designer:
UX (User Experience) and UI (User Interface) Designers are typically focused on the design side of the software, with a large emphasis on usability, functionality, and user experience. UI/UX designers should be involved as early as possible in the design process of any application or project, as their input will shape the usability of the product. For software development, designers typically approach software-design problems with a User Centered Design (UCD) approach. This process involves the user’s feedback at every step and is an iterative process.
Software Developer:
Developers write the code that builds the application based on a design that is provided by the UX/UI designer. This software may incorporate machine learning models. At a high level, developers can be grouped into Front-end, Back-end, and Full-stack developers. Here is a great video on the differences between the three. Front-end developers code the design created by the UI/UX designer, back-end developers connect applications, servers, and databases to make sure your product functions, and full-stack developers do it all.
Programming Language
A programming language is what the computer reads in order to do its tasks. Fortunately, in the 2020s, we have plenty of high-level programming languages at our disposal. We don’t need to deal with any 1s and 0s, and we can write code that is easy to read as a human, yet still fast for the computer to process.
Python
Python is one of the most popular languages for data science and machine learning. Languages like R and Julia are also great, but we are most experienced in Python and know these resources better. We assume you’re proficient in Python, but here are some resources if you’re learning.
Books
- Automate The Boring Stuff with Python (free + available for purchase)
- Start from nothing, learn some great data handling tricks
- Python 101 by Michael Driscoll
- Effective Python by Brett Slatkin
Udemy courses (wait until they are < $20)
- Complete Python Bootcamp from Zero to Hero (Udemy) (350k reviews)
- Python for Data Science and Machine Learning Bootcamp (Udemy) (100k reviews)
Python Libraries
NumPy
This is the standard numerical computing library for Python. Before starting any data science Python script, import NumPy to get started.
Pandas
A powerful library for cleaning and manipulating tabular data (data in tables, like you get from an excel file or CSV) and plotting. See the getting started guide and documentation.
The creator of Pandas, Wes McKinney, has a book and GitHub repository with code. It’s also covered in the Udemy Data Science Bootcamp course listed above.
Matplotlib
Math Plotting Library aka matplotlib is the quintessential library for visualizing data in Python. Here’s the website, tutorials for beginner/intermediate/advanced users, and examples of common uses. Pandas plotting functionality is built on top of Matplotlib, so you can call .plot() directly from a DataFrame. Seaborn is another visualization library you may encounter. It’s also built on top of matplotlib so has much of the same functionality, but extends matplotlib in a few areas.
Scikit-learn/sklearn
Scikit-learn and its family of related scikit tools, like scikit-image, scikit-network, or scikit-learn-extra, provide an immense number and type of tools for all kinds of data science. Powerful, already optimized tools for everything within the data science task list can be found in scikit-learn. Examples include supervised learning, clustering, dimensionality reduction, data preprocessing, scoring metrics, and on and on. Generally, most scikit tools are written as objects in Python. This means the general workflow with using a scikit tool consists of instantiating the tool as an object, fitting it to the data with its object methods, and then using the fit object on data for its specified purpose. Given the wide range of tools available and their ease of use, sklearn is often a good starting point for tools for any given data science project.
Package Managers
A package manager keeps track of all the packages (like those Python libraries above) you have on your computer or virtual environment. It allows you to easily install new packages and update the ones you have.
Pip
Pip is the Python language package manager that pulls packages from the Python Package Index (PyPI). You download packages like this:
pip install numpy
Conda
Conda is a language-agnostic package manager that pulls packages from the Anaconda repository.
conda install numpy
Development Environment
Your development environment is your workplace - it’s where you’ll spend most of your time. There are lots of different ways to develop code, so choose an environment that makes you comfortable.
Text Editors
A text editor is a simple, streamlined place to write code. That’s it. It can be notepad or something more slick. Many are free, and there are tons to choose from: Sublime is lightweight and wildly popular; Atom is customizable and links well with Git (and it can be made into an IDE - see below!); Vim is old-school and has great shortcuts to speed up your coding. The list goes on!
If you’re building something fast and easy, just like to keep things simple, or are a confident coder a clean text editor is the way to go.
IDEs
If you’re building a complex package with lots of dependencies, working with multiple languages, or developing something to be wrapped into software, an IDE may be what you’re looking for. An integrated development environment (IDE) is not just a code editor (which can be any text editor) but a toolset for debugging, testing, and execution. Here’s an overview of Python IDEs.
For non-Jupyter IDEs, it’s really up to preference. Atom is a solid choice, but some people love PyCharm for all the bells and whistles for debugging and syntax, others prefer Visual Studio code, which has an RStudio feel and some nice debugging features. Spyder also comes standard with Anaconda package manager. There are also collaborative, browser-based IDEs, such as Replit, that try to abstract away some of the friction of selecting an IDE. In the world of IDEs, don’t be overwhelmed with the large number of choices. Just start with one and work with it. Don’t switch until you have sufficiently worked with an IDE, no matter what it is. Sometimes it can be a while before you identify why you prefer one or the other. This kind of approach should be applied to almost anything in the computing industry.
Notebooks
Jupyter
Many data scientists use jupyter notebook because of the ease of experimenting and visualizing, though they’re not good for production coding and are prone to getting messy. Beginner’s Guide to Installing Jupyter Notebook Using Anaconda and Jupyter tutorial both show easy ways to get started with the Anaconda distribution. There may be locations to access Jupyter notebooks or other development environments on various DoD Networks. Jupyter notebooks are easily run in Azure ML studio or in AWS EC2 instances or within the AWS Sagemaker Service/Deep Learning AMIs. Deepnote is a free cloud-hosted and team-based Jupyter notebook environment designed for collaborative experimentation.
Colab
Don’t want to set up your own development environment? Need access to a GPU, but don’t want to pay for a cloud provider? Google Colab solves some of these problems and it’s pretty easy to use. Here’s a tutorial website we like.
If you’re looking for a quick environment to test out some ideas while saving the results to come back to later, notebooks are your best bet.
Terminals
Also called the command line and bash, a computer terminal is a way to interact with the computer directly without the graphical user interface (e.g. Windows). Think black screen with monospaced green text. You can use them to do all sorts of things (write files, navigate through your computer directories, interact with git), but you can also use them to run programs, including Python scripts.
While command-line interfaces can feel very foreign to those of us used to GUIs, they allow us to work with files in a far more powerful way than with GUIs. This is especially true when you’re working in cloud environments, which generally run through a command-line interfaces. I can’t say how many times terminal commands have saved me on AWS and Databricks when I was trying to move files from one storage location to another.
Simple commands like cd (change directory), ls (see files in a directory), mkdir (make a new directory/folder), mv (move), and rm (delete) can be very helpful.
Command Prompt
This is the basic Windows terminal. Search for ‘cmd’, and you’ll find it.
PowerShell
Windows created a fancier terminal to replace the base Command Prompt. This is PowerShell.
Terminal
This is the Mac terminal. They weren’t very creative with the name.
You could code data science projects directly in your terminal…but really this should be reserved for passing direct commands to your computer.
Check out these resources to learn more:
- 11 Reasons why data scientists should learn the command line
- Linux commands for beginners
- Intermediate Linux commands
Computing and Storage
You’ve got your team, your code, and your dev environment, but where does all the number-crunching happen? Where does the data live? There are a couple options. We’ll start small and go big.
Local
This is the computer that’s on your desk or in your lap. It’s obviously easy to use, but it probably doesn’t have too much oomph or space.
On Premise
These are servers that your organization might set up. They’re server stacks in cold rooms. The benefit of “on-prem” is that you have complete control over the server setup and how they’re managed. The drawback is that you’re responsible for server setup and how they’re managed and need to have someone on your team with those skills
Cloud
What’s the “cloud”? It’s servers that you don’t have to manage because a big cloud provider (think Amazon, Microsoft, Google) manages them. Nowadays, cloud computing is easy to leverage and you can spin up virtual machines, storage, and more with a few mouse clicks, a few minutes, and a credit card rather than needing to purchase your own gear and learn how to do it from scratch.
We’ve outlined the major players below. We have the most information on AWS because that’s the one we have the most familiarity with, but all their services are fairly comparable. You won’t go wrong choosing any of them, and there plenty of other smaller providers too if you want to choose something different.
Amazon Web Services
Check out these sites and resources for getting started:
- How to make an AWS Account
- Overview of AWS
- Udemy Course by “A Cloud Guru” (wait until price drops to < $20)
Key services in getting a prototype built:
- Elastic Compute (EC2) Compute resources for development, model training, or application hosting
- S3 (Cloud data storage)
- Sagemaker (Machine learning platform) AWS’s Jupyter Hub. Has AWS pre-built models or you can build your own.
- CodeCommit (AWS Git)
- IAM (team account/access management)
Articles:
- Deploying a Python Web App on AWS (TowardsDataScience)
- Setup and use Jupyter (IPython) Notebooks on AWS (TDS)
- Building a data pipeline from scratch on AWS (TDS)
Certifications
A note on certifications — the military highly values them, perhaps overly so in the context of data science. Taking a course to get one of these certifications is a license to learn, but not an end in itself. If you don’t use the skills, they will atrophy and all your left is a certificate. Also, don’t believe anyone who tells you that getting a single certification will get you a $200,000 salary as a civilian.
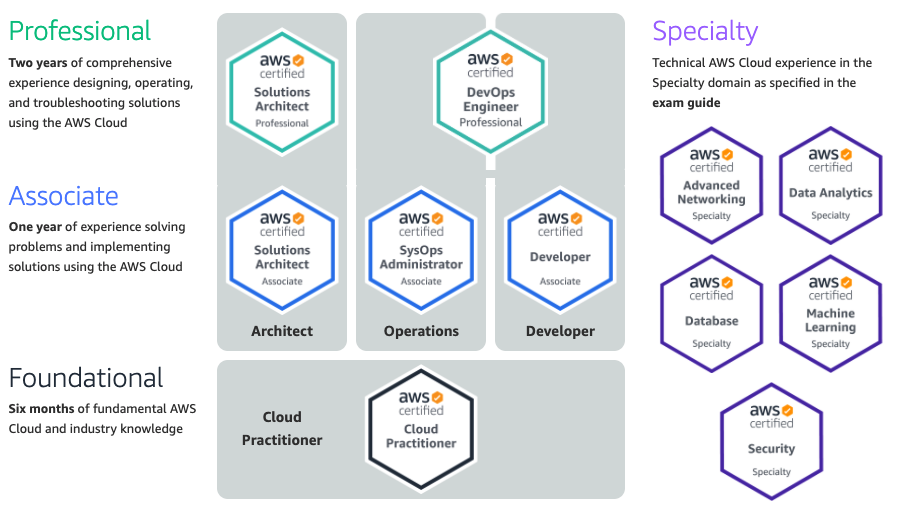
Available AWS Certification. Source
Microsoft Azure
Here’s an overview of Azure Certifications from Cloud Academy. Again, certifications are not an end in themself, but just one way of learning “enough to be dangerous” about the cloud resources you’ll need to build/deploy a product that helps your users.
Data must be stored within a storage account, within a container, and then finally within a blockblob (one data file per block blob). The containers can then be registered within your Azure ML Studio, where you do project work. Use the datastore feature to link to a container, and the datasets feature to link to a specific file within your datastore/container.
FastAI has a good setup guide. Ignore info about the library/course.
Google Cloud Platform
The Fast AI course has a good setup guide here. Ignore info about the fastai library or course itself
Databricks
Built on top of Azure, AWS, and Google Coud, Databricks is ideal for both smaller scale jobs / testing and also large scale jobs.
Deployment
What are the tools available for getting your tool or data science analysis to your user (besides powerpoint slides and excel spreadsheets…)
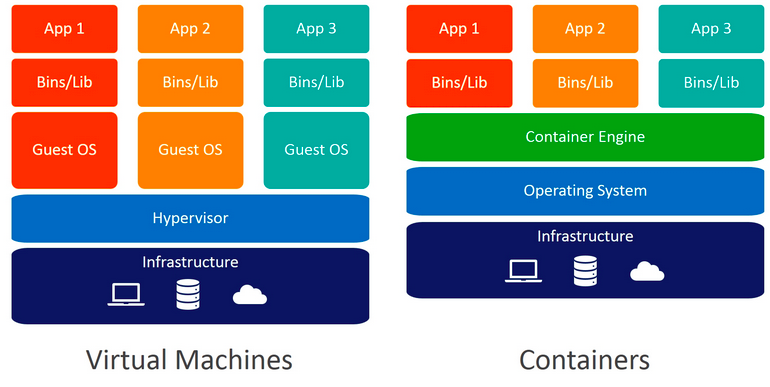
VMs vs Containers. Source
Dashboards
If your uses want interactive analytics, dashboards can be a good choice. You can host them on a local machine or easily deploy them on the web. A couple popular choices are: Tableau, Streamlit, Plotly Dash.
Docker
Docker is a popular container engine that enables rapid, repeatable deployment of software applications without the burden of creating and resourcing multiple VMs. In many respects a Docker container resembles a VM, but rather than emulating hardware (all the way down to baremetal), a Docker container emulates a subset of the OS kernel particular to your application needs. In basic terms, this means that you, the developer, can execute a few Docker commands and have an application-specific environment and all relevant libraries ready to go in minimal time. This process is repeatable multiple times on the same baremetal without compromising performance or risking system underutilization. A lot of bang for your buck.
Navigation
» About
» Recipes
» Resources
» Code examples