Often a customer (a boss, unit commander, or organization) wants AI for the sake of AI. Try to see past the hype (“build me some AI”) and look for the intention (“I need to predict X to add value to my organization”) so you can solve their problem. Instead of building a hand-crafted neural network or transfer-learning on the latest state-of-the-art model from Google or OpenAI, use the 80:20 rule. Get 80% of the results from 20% of the work by building a “stupid” baseline model.
Characteristics of a baseline model:
- Set a beatable standard. If you built a deep learning model that gets 85% accuracy, you may think that the results are pretty good. But if a simpler model (heuristic, linear regression, logistic regression) gets 83% accuracy, then you did a lot of work for not a lot of results. Maybe the extra 1% or 2% of accuracy is worth it, but if that comes at a cost of easier-to-break pipelines, more technical debt, or lack of explainability, then a baseline model might be best.
- Be simple. A simple model is less likely to overfit the data than a complex model. Remember, complex models fail in very complex ways. Keeping it simple allows you to troubleshoot more easily.
- Be interpretable. Explainability will help you to get a better understanding of your data and will show you a direction for feature engineering.
- Help expose data pipeline issues. If you can’t get your data processed and ready for an out-of-the-box scikit-learn model, you won’t be able to get it formatted for a PyTorch network.
A few useful baselines to consider:
- Guessing. If 83% of your data is labeled “0” and 17% is labeled “1”, you can achieve 83% accuracy just by predicting “0” regardless of the data. It’s dumb, (potentially) useful, and sets the minimum score to beat.
- This goes back to exploring your data. Imbalanced classes pose unique challenges that sometimes make problems like this better suited to anomaly detection (asking “what’s different?”) rather than standard classification (asking “what’s what?”).
- Linear Regression. Good for predicting continuous variables (price, age, test score)
- Logistic regression. Good for predicting categories (text topic, pass/fail, etc)
- Decision Trees. Can work for classification or regression, perform quite well out of the box, can give feature importances.
Choosing a model:
You’ve explored your data and know its ins and outs. You also have a strong understanding of what you’re using data science to discover. Armed with this information, you should have a general idea of what you can and should do with your data. Below we’ll outline a couple common modeling options (ordered in terms of complexity/interpretability). For more detailed descriptions check out this article.
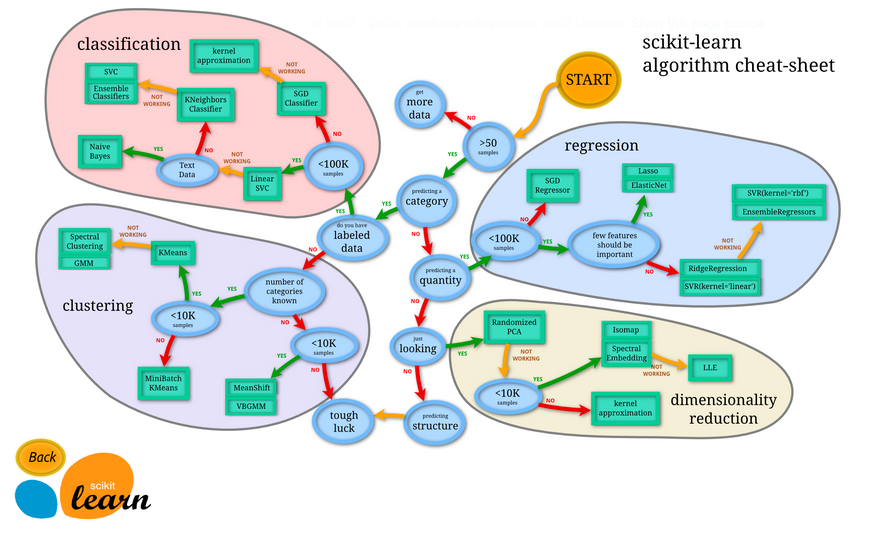
Choosing an estimator for your problem. Source
Types of Machine learning models:
Machine learning is an every-growing field, so there are many different types of learning, each with its own techniques and problems. Check out this article for a more comprehensive list of learning types. Here, we present three main types of learning problems: supervised, unsupervised, and reinforcement learning.
Supervised Learning Models:
This is when you want to learn a mapping between inputs and outputs, using labled data.
- Regression: Use this when you’re trying to estimate the relationship between the independent and dependent variables, oftentimes to make forecasts. Example methods: Linear regression, Logistic regression, Autoregressive Integrated Moving Average (ARIMA); Vector Autoregression (VAR), Support Vector Machines, Neural Networks
- Classification: Use this when you’re trying to predict what group new data belongs in. Example methods: Logistic regression, Decision Trees, Naive Bayes, Linear Discriminant Analysis, Support Vector Machines, k-nearest neighbors, Neural Networks
Unsupervised Machine Learning Techniques:
This is when you don’t have labled data and want to extract relationships from the data.
- Clustering: Use this when you want to explore the groups (e.g. topics) that your data may naturally fall into. Example methods: Hierarchical clustering, k-means.
- Anomaly detection: Use this when you’re trying to identify rare events.
Reinforcement Learning:
This is when you have an agent that interacts with an evnironment and learns via feedback from that environment.
- As oposed to fixed-dataset learning methods (e.g., supervised ML), RL is best suited for interactive models and problems with sequential and co-dependent decisions (e.g., game play, personalized recommendations, autonomous driving, etc.). The agent learns a strategy to to map situations to actions, in order to maximize a reward.
- Although RL is ussually less data intensive, it can be more mathematically/computationally complex. You have to be able to model/simulate the feedback from the environment. This environment can be as simple as a 0/1 (as in the multi-armed bandit algorithms) or as complex as 3d space (for autonomous drones). Here is a good collection of pre-built environments from OpenAI.
Useful Resources
- “First Create a Common Sense Baseline” - Towards Data Science
- “How to Build a Baseline Model” - Towards Data Science
- “How to Create your First Machine Learning Model” - Towards Data Science
- “A Summary of the Basic Machine Learning Model” - Towards Data Science
Navigation
» Previous recipe
» Next recipe
» About
» Ingredients
» All recipes
» Resources
» Code examples